Автоматизация анализа анкетных данных
П. С. Ростовцев
Почти всегда прикладные исследования проводятся в состоянии цейтнота: необходимо выдать результаты обработки собранных данных к ближайшему выпуску газеты или проанализировать ситуацию до предстоящего совещания на высшем уровне, заседания городского совета, ускорить маркетинговые исследования и т. п.
В фундаментальных исследованиях много сил и средств идет на рутинную работу: подобрать интервалы для количественных переменных, так скомпоновать таблицу, чтобы закономерность прослеживалась наиболее явственно, наконец построить типологию, объединив содержание массы таблиц – все это требует колоссальных затрат времени и умственной энергии.
Надежен ли полученный результат? Может быть при повторном обследовании мы получим обратное? Эти вопросы важны и в прикладных и в фундаментальных исследованиях.В данной работе мы представим краткий обзор методов программного обеспечения, разработанных в Институте экономики и организации производства СО РАН (Новосибирск), предназначенных для автоматизации, увеличения эффективности и надежности анализа социально-экономических данных. Для иллюстрации применения методов используются данные различных социологических исследований, проведенных отделом социальных проблем Института экономики и ОПП СО РАН. Основные результаты данной работы ранее изложены в работе [8].
Ввод данных.Автоматизация обработки информации начинается с подготовки информации. Здесь нами используется в качестве экранных форм текст анкеты, непосредственно созданный для опроса. Если позволяют условия, может производиться компьютерный опрос. Логика опроса и контроль ввода программируются исследователем (не специалистом в программировании). До появления этого инструмента подобным инструментом являлась программа DATA ENTRY в статистическом пакете SPSS, однако, он был сложен для применения его социологом-практиком.
Устойчивость результатов. Для проверки устойчивости результатов мы применяем имитацию повторного сбора данных – метод BootStrap [11, 13]. Имитация состоит в выборке с возвращением и повторном вычислении статистик и структур данных.
Таблицы сопряженности. Этот наиболее распространенный инструмент исследования данных [1] мы развили в настоящее время для исследования связи между не альтернативными вопросами (типа меню). Кроме частот и процентов в число статистик ячеек таблицы мы включили средние по внешней переменной, значимости и BootStrap-значимости смещений средних и частот. BootStrap-значимость полезна при исследовании “взвешенных” данных, когда классические методы бессильны. В табл. 1 сопоставлено использование классического метода (критерия Стьюдента) и применение BootStrap-значимости. В ней сравниваются средние в группах, определяемых ячейками таблицы, с остальной совокупностью. Хотя применение критерия Стьюдента в данном случае не вполне корректно, складывается ясное впечатление о сопоставимости результатов.
|
ценность |
|
|
|
|
|
| Друзья |
|
|
|
|
39,24
|
|
Значимость
|
|
|
|
|
|
|
Bootstr.-знач.
|
|
|
|
|
|
| Работа |
|
|
|
|
41,21
|
|
Значимость
|
|
|
|
|
|
|
Bootstr.-знач.
|
|
|
|
|
|
| Семья |
|
|
|
|
|
|
Значимость
|
|
|
|
|
|
|
Bootstr.-знач.
|
|
|
|
|
|
| Материальное
благополучие |
|
|
|
|
|
|
Значимость
|
|
|
|
|
|
|
Bootstr.-знач.
|
|
|
|
|
|
| Здоровье |
|
|
|
|
|
|
Значимость
|
|
|
|
|
|
|
Bootstr.-знач.
|
|
|
|
|
|
| По
всей
совокупности |
|
|
|
|
|
Исследование структур данных. Распространенным методом анализа структуры данных является кластерный анализ [3]. Объекты этим методом распределяются по кластерам в соответствии с их близостью. Некоторые методы позволяют проводить прямую кластеризацию таблицы данных, выявляя в ней структуру из однородных прямоугольников [2, 14]. Точным обоснованным выводам статистического характера о кластерной структуре уделяли внимание Бокк и Хартиган [12, 14] – их исследования показывают сложность решения проблемы традиционными параметрическими методами.
Устойчивость метода "k средних". Мы снабдили средствами исследования устойчивости результатов работы этого метода. Суть метода состоит в генерировании выборки с возвращением из исходных данных, и проведении классификации методом "k средних" с использованием в качестве начальных центров, полученных на исходных данных. Это позволило, в отличие от их исследований, оценивать устойчивость отдельных объектов, классов, и классификации в целом.
Структура таблиц данных. Для анализа небольших данных, таких, как таблица сопряженности нами разработан алгоритм разделения матрицы данных на однородные связные области. Такая свободная форма областей является достижением данного метода. В основе алгоритма – упорядочение строк и столбцов, агломеративная процедура объединения кластеров и перемещение их границ.
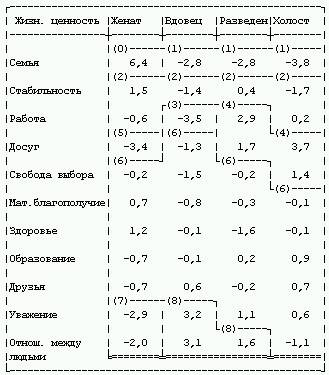
В табл. 2 представлены результаты исследования структуры областей для таблицы стандартизованных отклонений частот от их ожидаемых значений. Из таблицы ясно видно, например, что ценность женатых (замужних) – семья, у вдовых ценности – уважение и отношения между людьми, зато работа не является ценностью.
Устойчивость структуры таблицы сопряженности. Имитация повторного сбора данных (BootStrap) вызывает “возмущение” элементов таблицы и изменение структуры кластеров (рис. 1).
Процедура имитации повторного сбора данных позволяет оценить устойчивость элементов таблицы в кластерах и устойчивость упорядочения строк и столбцов.
Основные тенденции связи. Черно-белый анализ связи переменных. Необъятность таблиц стимулировала появление множества методов исследования таблиц сопряженности [1, 4, 5, 10]. Эти методы позволяют выявить соответствия и даже провести оцифровку значений переменных, но оставляют за исследователем работу по интерпретации шкал.
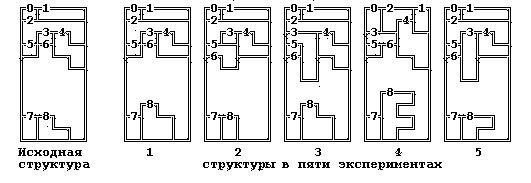
Рис 1. Эксперименты
по проверке устойчивости структуры областей таблицы
Z-отклонений (связь жизненных ценностей и семейного положения,
табл.
2).
Предлагаемый метод состоит
в поиске такого дихотомического ("черно-белого") разбиения значений двух
переменных, чтобы четырехклеточная таблица сопряженности агрегированных
переменных была максимально контрастной. Критерием контрастности является
смещение частоты в первой ячейке таблицы от ожидаемого значения. Мы пытаемся
разделить совокупность по каждой из участвующих переменных на 2 группы,
отражающие два полюса в значениях переменных – “черное–белое”, "богатые–бедные",
"старые–молодые", "должно-
сти прибыльные–неприбыльные";
группировка происходит одновременно по двум переменным. Исследование устойчивости
позволяет выявить нечеткость соответствия значений переменной полюсам.
Преимущество, к которому мы стремимся – это простота интерпретации. Имитация
повторного сбора данных размывает границы “черного и белого”, внося полутона
в такой анализ.
| Проф.образование
(низкий уровень) |
Курсы | ПТУ, ФЗУ, РУ | Нет проф.образования |
| »Степень
серости» |
0% | 4% | 14% |
| Проф.образование
(высокий уровень) |
Высшее | Среднее специальное | Другое |
| Проф.образование
(высокий уровень) |
87% | 100% | 100% |
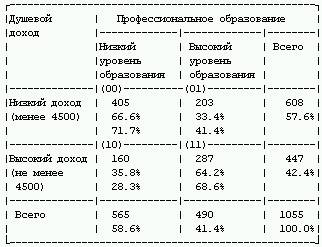
Табл. 4 и 5 показывают размытость классификаций – “степень серости” каждого значения, которая является долей случаев, когда значение оказывалось в 1-м классе. Таким образом, значение переменной “образование” – “курсы” прочно осело в нулевом классе, а среднее специальное – в первом.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Автоматизация построения типологий. Типологией называется логическое разделение совокупности объектов на качественно различные группы объектов – типы [7].
В соответствии с таким пониманием типологии мы рассматриваем множество целевых переменных, по которым оценивается качество группирования, и множество группировочных переменных, используемых для построения логики группирования. Таким образом, основная идея автоматизации типологического группирования заключена в рабочей формуле:
Типология = Логика Группирования + Цель Группирования
Формальной целью группирования
является разделение совокупности объектов (анкет) на классы, различающиеся
по множеству "зависимых" переменных Y={Y1,...,Yn};
для формирования логики группирования используется множество "независимых"
переменных X={X1,...,Xm}
Типология здесь – разбиение
R={R1,...,Rk}
совокупности объектов на классы (типы), оптимальное с точки зрения его
связи с целевыми переменными
Y, построенное с использованием
логики группирования объектов по множеству "независимых" переменных X.
Типология строится в виде дерева группирования по переменным X,
вершины которого объединяются в классы – типы. При построении классификации
R
мы ограничиваем сложность логики группирования формальными критериями (число
вершин в дереве группирования, число типов, размер групп и т. п.); при
построении типологии в диалоговом режиме, который в настоящее время считается
основным, сложность группирования определяется из содержательных соображений.
В отличие от известных методов [6, 15] в качестве критерия классификации (типологии) мы используем внутриклассовый разброс [10], как это делается в ряде алгоритмов кластерного анализа [4], однако здесь используется модификация критерия, позволяющая работать как с количественными, так и с неколичественными переменными.
Для демонстрации дерева
группирования воспользуемся типологией (рис. 2), построенной по переменным
(X) "Пол", "Возраст", "Семейное положение" и "Образование". В качестве
независимых переменных (Y) взяты дихотомические переменные – индикаторы
того, являются ли жизненными ценностями респондентов "Семья" и "Будущее
детей". Заметим, что хотя признак "Возраст" принимал участие "в конкурсе"
переменных для группирования данных, он не участвовал в логике группирования.
Для характеристики дерева группирования по зависимым переменным представим
таблицу процентного распределения целевых переменных (табл. 6).
|
Тип |
|||||
|
|
|
|
|||
|
|
330 Семейное положение: женат | ||||
|
|
51 Образование: неполное среднее | ||||
|
|
81 Образование: общ.среднее, проф.-техническое | ||||
|
|
198 Образование: среднее специальное, высшее | ||||
|
|
104 Семейное положение: разведен, вдов | ||||
|
|
15 Пол: мужской | ||||
|
|
89 Пол: женский | ||||
|
|
81 Семейное положение: холост (не замужем) | ||||
Рис. 2. Типология населения по ориентации на семейные ценности. Структура строки рисунка: номер группы, символ “<“, если группа разбивается, символ “*” с последующим за ним номером типа, если группа представляет висячую вершину; описание вершины (группы): число объектов, переменная и список значений, ее идентифицирующих
|
|
|
|
|
|
|
|
|
|
| Группа 3 |
|
|
|
| Группа 7 |
|
|
|
|
|
|
|
|
| Группа 6 |
|
|
|
|
|
|
|
|
| Группа 4 |
|
|
|
| Группа 5 |
|
|
|
| Группа 8 |
|
|
|
*) Взвешенное число объектов
Устойчивость типологического группирования исследуется на локальных шагах разбиения. Для этого классификация получается многократно на сгенерированных данных и сравнивается с классификацией на исходных данных.
Внутренняя типология. Не всегда при построении типологии задается множество целевых переменных, иногда нужно разумно логически разделить совокупность объектов на типы по заданным переменным, не более того. В этом случае целью является сжатие информации в одну классификацию. Задача кластерного анализа весьма близка к такой постановке, однако, при ее решении не дается логика группирования. Нашими средствами такая задача решается за счет задания в качестве целевых и группировочных признаков одного и того же множества признаков.
Именно так решена нами задача построения типологии по жизненным ценностям,
которым в данных соответствовали дихотомичес-
кие переменные "Свобода", "Будущее детей", "Карьера", "Семья", "Ма-
териальное благосостояние", "Власть", "Здоровье", "Любимое дело".
Типология, по-существу, состоит из трех вершин дерева: группы 3 (тип
3, полученный объединением групп 7 и 8), респондентов, не ценящих ни будущее
детей, ни карьеру; группы 4 (тип 1) – ценителей карьеры, не думающих о
детях; группы 2 (тип 2, объединение групп 5 и 6) – ценители детей.
Рис. 3. Дерево группирования по жизненным ценностям
Эта типология, вероятно, слишком бедна и лучше остановиться на типологии, которую дает разбиение без синтеза типов:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Будущее детей |
100,0
|
100,0
|
0,0
|
0,0
|
0,0
|
| Семья |
67,9
|
56,8
|
30,3
|
40,7
|
29,2
|
| Здоровье |
69,0
|
65,7
|
57,9
|
62,2
|
37,2
|
| Матер.благопол. |
100,0
|
0,0
|
36,0
|
50,8
|
94,6
|
| Любимое дело |
5,1
|
28,6
|
0,0
|
100,0
|
32,1
|
| Свобода |
14,8
|
25,6
|
15,5
|
38,0
|
62,5
|
| Карьера |
2,7
|
3,2
|
0,0
|
0,0
|
100,0
|
| Власть |
0,0
|
0,9
|
0,6
|
1,2
|
3,4
|
Перспективы. В настоящее время идет работа по созданию небольшой системы программ, объединяющей разработанные методы. Круг решаемых задач будет расширяться с целью типологического анализа сложных явлений. Эта задача была предметом “соревнования” многих статистиков при сравнении средних в дисперсионном анализе [10]. Наш опыт здесь состоит в сравнениях групп в детерминационном анализе, основанном на простых статистиках [9], и эту область предстоит расширить.
Литература
1. Аптон Г. Анализ таблиц сопряженности. – М.: Финансы и статистика, 1982.
2. Браверман Э. М., Мучник И. Б. Структурные методы обработки эмпирических данных. – M.: Наука, 1983.
3. Дюран Б., Оделл П. Кластерный анализ. – М.: ИЛ, 1977.
4. Енюков И. С. Методы, алгоритмы, программы многомерного статистического анализа. – М.: Финансы и статистика, 1986.
5. Жамбю М. Иерархический кластерный анализ и соответствия// Финансы и статистика, 1988.
6. Лбов Г. С. Методы обработки разнотипных экспериментальных данных. – Новосибирск: Наука, 1981. 1983.
7. Плошко Б. Г. Группировка и системы статистических показателей. – М.: Статистика, 1971.
8. Ростовцев П. С. Смирнова Н. Ю., Корнюхин Ю. Г., Костин В. С. Анализ структур социологических данных. Устойчивость// Анализ и моделирование экономических процессов переходного периода в России. Вып. 2. – Новосибирск: ИЭиОПП СО РАН, 1997.
9.
Ростовцев П. С. Статистические характеристики детерминации//
Статисти-
ческое
моделирование экономических процессов. – Новосибирск, Наука, 1991.
10. Шеффе Г. Дисперсионный анализ. М.: 1963.
11. Эфрон Б. Нетрадиционные методы многомерного статистического анализа. – М.: Финансы и статистика, 1988.
12. Bock H. H. On some significance tests in cluster analysis// Journal of Classification, 1985. № 1
13. Efron B. Better bootstrap confidence intervals// J. Amer. Statist. Ass., 81, 1986.
14. Hartigan J. A. Clustering algorithms/ Wiley. – N.Y.: 1975.
15. SPSS for Windows. Chaid. – Chicago: 1993.