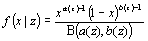
Распределение случайной величины дает наиболее полное статистическое описание наблюдаемых объектов. В работе рассматривается метод восстановления функции условного распределения случайной величины x путем ее аппроксимации Бета-распределением. Коэффициенты Бета-распределения a и b отыскиваются в виде функций от произвольного параметра z. Зависимости a(z) и b(z) аппроксимируются одномерными кубическими сглаживающими сплайнами. Определение оптимальной степени сглаживания рассматривается как статистическая задача о распределении регрессионных остатков. Регрессионные остатки измеряются значимостью отклонения эмпирического условного распределения от теоретического (восстановленного) по непараметрическому тесту Колмогорова-Смирнова. Возможности метода проверяются на специально сгенерированных тестовых выборках различного объема.
Входными данными для рассматриваемого метода восстановления двумерного распределения является выборка из N наблюдений, описываемая случайными величинами x и z. Предполагается, что x изменяется в интервале (0,1) и условная плотность распределения f(x|z) может быть аппроксимирована Бета-распределением с параметрами a(z), b(z):
| (1) |
Зависимость параметров a и b от z может быть достаточно сложной. Поэтому для ее восстановления необходимо выбрать класс функций, позволяющий строить приближение практически любой функции и при этом полностью контролировать точность аппроксимации. С учетом этих требований мы выбрали кубические сглаживающие сплайны, математический аппарат построения которых описан в [2, с.54-58 и 3, с. 194-213], а программный код открыто выложен в интернете [4].
Первым шагом восстановления двумерного распределения является выбор значений zi, i={0,1, : , m}, которые разбивают весь диапазон изменения z на интервалы (zi-1,zi). Число интервалов выбирается, исходя из двух противоположных требований. Во-первых, каждый интервал должен быть достаточно широким (содержать много наблюдений), чтобы получить хорошие оценки значений ai и bi. Во-вторых, интервалы не должны быть широкими, чтобы не терять информацию о зависимости a и b от z в процессе усреднения. Итак, следует избегать как слишком малого числа интервалов, так и слишком большого.
Кроме количества интервалов, необходимо выбрать и способ разбиения. Здесь существует по крайней мере два решения.
Во-первых, сетка с равномерным шагом, где шаг сетки:
| h=(zm-z0)/N | (2) |
Во-вторых, сетка с равнонаполненными ячейками, где объем i-ой ячейки:
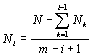 , i={1,:,m} , i={1,:,m} | (3) |
Процедура разбиения немного усложняется в том случае, когда наблюдения с одним и тем же z оказываются в разных ячейках.
Если наблюдения распределены равномерно по z, то имеет смысл выбрать равномерную сетку, если же нарушения равномерности существенные, то лучшим вариантом будет разбиение по квантилям.
После разбиения выборки на ячейки по z, можно переходить к вычислению ai и bi для каждой ячейки i={1, : , m}. Получить оценки параметров ai и bi проще всего методом моментов:
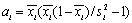 | (4) |
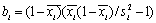 | (5) |
где 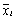 - выборочное среднее x, а
- выборочное среднее x, а 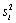 - выборочная дисперсия (смещенная).
- выборочная дисперсия (смещенная).
Альтернативный способ получить оценки a и b основан на процедуре максимизации функции правдоподобия, имеющей смысл вероятности совместного наблюдения выборочных данных xj при имеющейся плотности распределения (1):
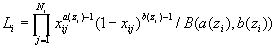 | (6) |
Учитывая ограничения точности и диапазона представления чисел в компьютере, удобнее оптимизировать не саму функцию правдоподобия, а ее логарифм, вместо произведения накапливая суммы:
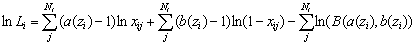 | (7) |
Процедура генерации выборки включает следующие шаги:
1. Задание границ изменения z: (zmin, zmax).
2. Задание функциональной зависимости a(z) и b(z).
3. Задание объема выборки N.
Генерация каждого из N наблюдений:4. Генерация псевдослучайного числа z в интервале (zmin, zmax).
5. Определение параметров Бета-распределения по z: a(z) и b(z).
6. Генерация псевдослучайного числа P в интервале (0, 1). Здесь P имеет смысл вероятности.
7. Определение x, при котором интегральная функция распределения принимает значение P:
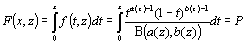 | (8) |
8. Добавление полученных значений {z, x} к выборке.
Проиллюстрируем выполнение этой процедуры на примере.
1. Границы изменения z:
zmin = 0, zmax = 100.2. Зависимости a(z) и b(z):
| a(z) = 0.5 + 0.05oz | (9) |
| b(z) = 5.5 - 0.05oz | (10) |
3. Объем выборки N:
N = 400Генерируем первое из 400 наблюдений:
4. Генерируем случайное число z в интервале от 0 до 100:
Z = 73.0095. Определяем параметры Бета-распределения:
| a(73.009) = 0.5 + 0.05o73.009 = 4.150 |
| b(73.009) = 5.5 - 0.05o73.009 = 1.850 |
6. Генерируем случайное число P в интервале от 0 до 1:
P = 0.3544631267. Определяем x, при котором интегральная функция распределения принимает значение
x = 0.6394
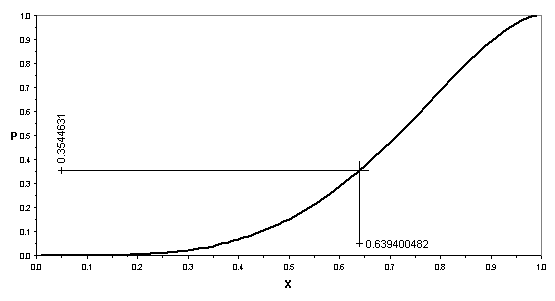
Рисунок 1. Преобразование равномерно распределенного случайного числа P в наблюдаемое значение x по Бета-распределению F(x,a(z),b(z))
8. Добавляем полученные значения {z=73.009, x=0.6394} к выборке:
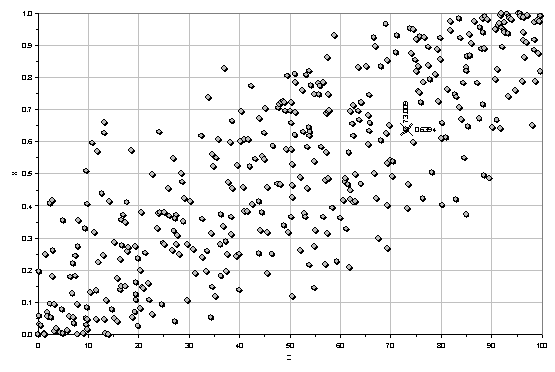
Рисунок 2. Выборка из 400 наблюдений по Бета-распределению с параметрами (9, 10). Крестиком обозначено наблюдение {z=73.009, x=0.6394}.
После того, как интервалы будут получены, можно приступать к расчету ai и bi. Для этого достаточно вычислить на каждом интервале среднее значение 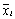 и смещенную оценку дисперсии
и смещенную оценку дисперсии 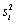 :
:
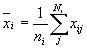 | (11) |
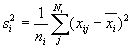 | (12) |
После этого можно рассчитать ai и bi, применив формулы (4) и (5). Если мы хотим получить оценки методом максимального правдоподобия, необходимо найти максимум логарифма функции правдоподобия (7). А в качестве начального приближения при поиске максимума можно воспользоваться только что полученными (методом моментов) оценками ai и bi.
При разбиении приведенной выше выборки на 10 равных интервалов мы получим следующие результаты:

где Zi-1-Zi - границы ячейки, Ni - число наблюдений в ячейке, 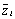 - среднее значение z в ячейке,
- среднее значение z в ячейке, 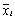 - среднее значение x в ячейке i, рассчитанное по формуле (11),
- среднее значение x в ячейке i, рассчитанное по формуле (11), 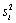 - смещенная оценка дисперсии в ячейке (12), aiz - теоретическое значение, рассчитанное по формуле (9), aimoment - оценка ai по методу моментов (4), aimaxL- оценка ai по методу максимального правдоподобия, biz - теоретическое значение, рассчитанное по формуле (10), bimoment - оценка bi по методу моментов (5), bimaxL- оценка bi по методу максимального правдоподобия.
- смещенная оценка дисперсии в ячейке (12), aiz - теоретическое значение, рассчитанное по формуле (9), aimoment - оценка ai по методу моментов (4), aimaxL- оценка ai по методу максимального правдоподобия, biz - теоретическое значение, рассчитанное по формуле (10), bimoment - оценка bi по методу моментов (5), bimaxL- оценка bi по методу максимального правдоподобия.
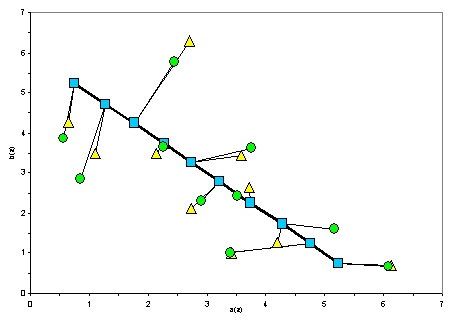
Рисунок 3. Параметры Бета-распределения ai и bi: квадраты - теория, треугольники - метод моментов, кружки - метод максимального правдоподобия.
Как видно из таблицы и рисунка, параметры распределения, восстановленные по случайной выборке, достаточно сильно отклоняются от теоретически заданных. Видно, что не сохраняется монотонность изменения параметров распределения. Иными словами, в восстановленном таким путем двумерном распределении слишком велик уровень статистического шума, который не позволяет увидеть теоретически заложенной в выборке линейной зависимости a и b от z. Этот шум обусловлен случайным характером формирования выборки и не может быть преодолен иначе, как увеличением ее объема.
В данной работе мы ставим перед собой задачу найти такой способ восстановления параметров Бета-распределения, который позволит максимально точно восстановить как отдельные значения, так и характер зависимости a и b от z, сведя к минимуму разрушительное действие статистического шума.
Поиск необходимого класса функций начался с полиномов, коэффициенты которых легко определяются из требования минимизации суммы квадратов отклонений значений полинома от эмпирических точек. Но аппроксимация полиномами обладает весьма существенными недостатками.
Во-первых, для полиномов легко подобрать примеры практически неаппроксимируемых функций. В качестве такого примера можно привести ступенчатую (S-образную) кривую с длинными хвостами. Ни один полином конечной степени не в состоянии дать ее удовлетворительное приближение.
Во-вторых, для сглаживания полиномами нет другой возможности управлять степенью сглаживания, кроме изменения степени полинома. А это очень грубая настройка хотя бы в силу того, что она дискретна.
В то же время в последние десятилетия интенсивно развивается новый раздел современной вычислительной математики - теория сплайнов. Сглаживающие сплайны позволяют не только хорошо интерполировать функции по отдельным точно заданным значениям, но и эффективно строить аппроксимацию эмпирических данных с заданной точностью. При минимальной точности мы получаем чисто линейную зависимость с равной нулю второй производной на всей области определения сплайна. При максимальной точности сплайн становится интерполирующим, то есть проходит строго через все точки. В промежутке от минимальной до максимальной точности параметр сглаживания меняется непрерывно, позволяя найти оптимальную степень сглаживания.
Итак, сплайны действительно являются подходящим классом функций, в точности удовлетворяющим выдвинутым требованиям.
Выбранный нами вид сглаживающих сплайнов [см. 2, 4] минимизирует усредненный квадрат второй производной по всей области определения функции:
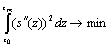 | (13) |
Кроме того, выполняется ограничение на отклонение сплайна от эмпирически заданных точек:
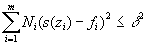 | (14) |
Здесь квадраты отклонений взвешиваются на количество точек в интервале i, поскольку точность определения значений fi обратно пропорциональна корню из Ni:
 | (15) |
Если мы зададим 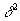 в ограничении (14) равной остаточной дисперсии для случая линейной регрессии , то сплайн выродится в линейную функцию от z. Если задать равным нулю, то сплайн станет интерполирующим и будет проходить через все эмпирические точки fi.
в ограничении (14) равной остаточной дисперсии для случая линейной регрессии , то сплайн выродится в линейную функцию от z. Если задать равным нулю, то сплайн станет интерполирующим и будет проходить через все эмпирические точки fi.
Для удобства параметризации степени сглаживания вместо будем использовать безразмерный параметр точности 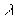 :
:
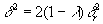 | (16) |
При уменьшении 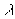 от 1 до 1/2
от 1 до 1/2 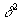 возрастает от 0 до
возрастает от 0 до 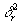 . Таким образом, задает точность аппроксимации, нормированную на единицу. Точность, равная единице, будет означать абсолютную точность. Точность, равная ?, будет означать точность линейного приближения. Точность меньше 1/2 не будет приводить к дальнейшему огрублению приближения, если пользоваться тем же алгоритмом. Для обобщения мы искусственно продолжим эту зависимость. Что может быть грубее линейной зависимости? Естественно, только отсутствие всякой зависимости, то есть константа. Тогда точность между 1/2 и 0 будет соответствовать переходу от линейного приближения к среднему значению f:
. Таким образом, задает точность аппроксимации, нормированную на единицу. Точность, равная единице, будет означать абсолютную точность. Точность, равная ?, будет означать точность линейного приближения. Точность меньше 1/2 не будет приводить к дальнейшему огрублению приближения, если пользоваться тем же алгоритмом. Для обобщения мы искусственно продолжим эту зависимость. Что может быть грубее линейной зависимости? Естественно, только отсутствие всякой зависимости, то есть константа. Тогда точность между 1/2 и 0 будет соответствовать переходу от линейного приближения к среднему значению f:
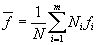 | (17) |
Имеет смысл дополнить область изменения еще одним значением: -1. Этому значению можно сопоставить отсутствие не только изменений в распределении, но и фактически отсутствие самого распределения. Для параметров Бета-распределения это означает их равенство единице, при котором распределение вырождается в равномерное.
Изменение кривой, аппроксимирующей зависимость a(z), при изменении параметра точности от -1 до 1 можно видеть на следующем рисунке:
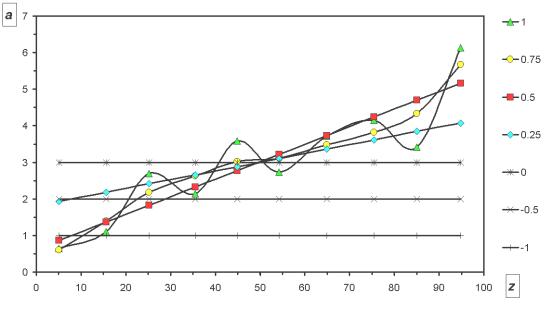
Рисунок 4. Восстановление a(z) с разной точностью аппроксимации.
В фазовом пространстве {a,b} это же будет выглядеть так:
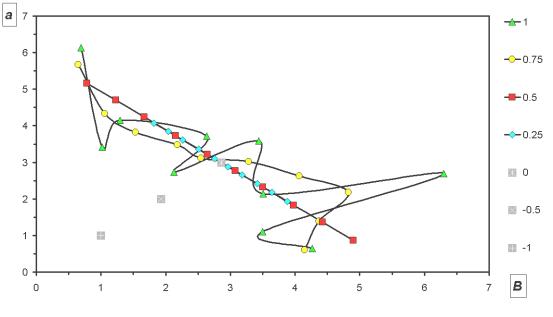
Рисунок 5. Восстановление {a(z), b(z)} с разной точностью аппроксимации.
Определив вид функции, которая может аппроксимировать параметры распределения с контролируемой точностью, остается найти критерий, который позволит определить оптимальное значение точности.
Отклонения параметров ai и bi от теоретических значений a(zi) и b(zi) имеют стохастическую природу, то есть вызваны случайным характером формирования выборки. Гипотеза о том, что эти отклонения действительно случайны, а не носят систематический характер, поддается проверке. В математической статистике хорошо известен непараметрический критерий Колмогорова-Смирнова, который позволяет проверить гипотезу о случайности отклонения эмпирического распределения Fn(x) от известного теоретического F(x) на основании статистики Dn:
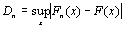 | (18) |
Чем больше значение статистики Dn, тем с меньшей вероятностью можно получить его случайно. Чтобы отвергнуть гипотезу о случайности отклонения, эта вероятность должна быть достаточно мала, меньше некоторого порога, например 5% или 0,1%. Но так поступают при сравнении единственного имеющегося у исследователя эмпирического распределения с теоретическим. Мы же имеем дело с целым набором из m эмпирических распределений (по одному на каждый интервал zi-1-zi, где i=1..m), каждому из которых соответствует свое теоретическое (восстановленное) распределение. Оказывается, что и в этом случае процедура принятия решения о случайности наблюдаемых отклонений в распределениях ненамного сложнее. Действительно, для этого достаточно отметить тривиальное свойство вероятности, рассчитываемой по статистике Dn. Если гипотеза о случайном отклонении эмпирических распределений имеет место, то рассчитываемая по критерию Колмогорова-Смирнова вероятность будет распределена равномерно.
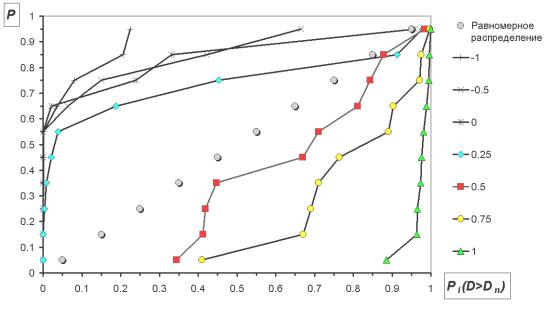
Рисунок 6. Зависимость формы распределения от точности аппроксимации.
Отсюда сразу вытекает формулировка критерия оптимальности: при наилучшем сглаживании параметров Бета-распределения наблюдается наиболее близкое к равномерному распределение вероятностей , вычисленных для всех интервалов (i) по критерию Колмогорова-Смирнова. Для определения близости этого распределения к равномерному можно еще раз использовать тот же критерий (Колмогорова-Смирнова), взяв на этот раз в качестве теоретического распределения равномерное.
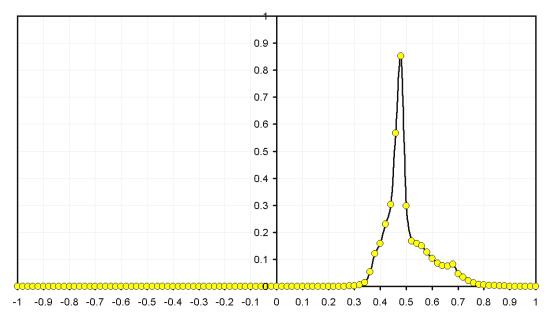
Рисунок 7. Поиск оптимальной точности аппроксимации по максимальной близости распределения к равномерному.
Изменение плотности условного распределения на сетке из 10 интервалов в результате сглаживания, можно видеть на рис. 8 и 9.
Другое
|
|
|
|
|
| Социально-психологические |
|
|
|
| Статусные |
|
|
|
| Обстановка в стране |
|
|
|
Приведенные в таблице данные можно интерпретировать следующим образом. Во-первых, социально-психологческие достоинства перекрывают их недостатки в занятиях предпринимательством, причем весьма существенно. Иными словами, в социально-психологическом плане опрошенные оказываются наиболее подготовленными к бизнесу. То, что заложено природой, воспитанием – это присутствует в избытке. Достаточно в целом и “статусных” характеристик: подходящий возраст, образование, налаженные связи в деловом мире и пр. Иное дело социально-экономическое положение в стране: здесь минусы перевешивают плюсы. Самым сильным тормозом в развитии предпринимательства данной группы бизнес-леди является неблагоприятная социально-экономическая обстановка в стране.
Кто защитит интересы женщин-предпринимателей?
* * *
Завершая анализ, отметим следующие моменты: